The original document describing XMP metadata usage with Recoll was written by Jeffrey Dick and is still available here. However it described using the old shell-based PDF Recoll input handler, which differs a lot from doing something equivalent with the current Python-based one (for which XMP capability is available from recoll 1.23.2, but the new handler can be used with previous Recoll versions).
I based this page on the text by Jeffrey Dick, using input from Johannes Menzel for all examples about the new features. The discussion which led to the updated handler is a Bitbucket Recoll issue.
Introduction
Organizing and searching a large collection of PDFs as part of a research project can be a demanding task. XMP metadata stored in a PDF, such as journal title, publication year, and user-added keywords, are often useful when searching for a publication.
Here, we describe customizing Recoll to retrieve this metadata, store it, and defining a result paragraph format to display it. See also a related wiki entry, Generating a custom field and using it to sort results, for sorting results on PDF page count.
Saving metadata to PDFs
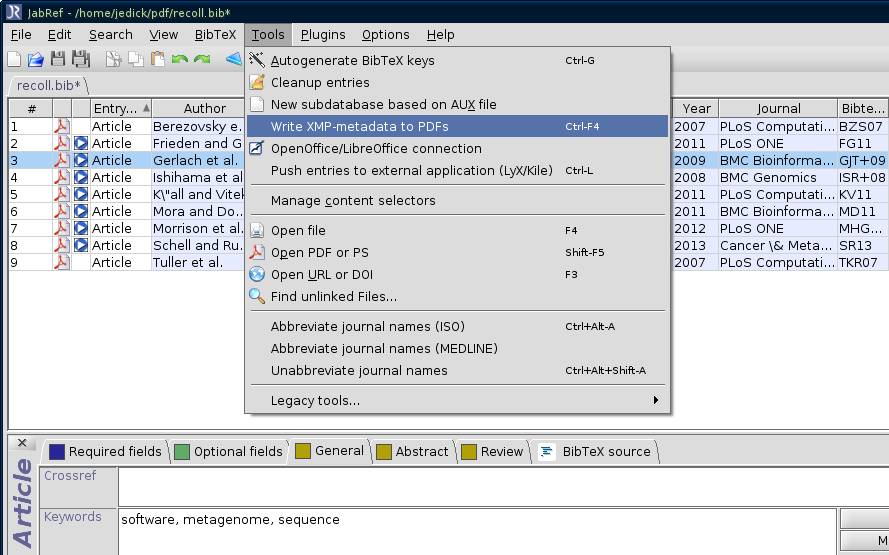
Bibliographic metadata can be saved in the PDF file itself. In the JabRef bibliography manager, this is done with the "Write XMP-metadata to PDFs" menu item. Note the presence of the keywords in the screenshot below; this field is a good place to tag the PDF with any words of your choosing to describe genre, topic, etc.
Custom indexing short example (fields file)
The following example (extract from a complete configuration shown later) creates two fields named "refjournal" and "refpages", which are both stored (so they can be displayed in result list entries), and indexed (you can specifically search them).
Some other types of metadata, such as title, author and keywords, are already indexed by Recoll (the default rclpdf finds them using the pdftotext command) so there is no need to add those to the [prefixes] section.
This is taken from the fields file inside the configuration
(e.g. '~/.recoll/fields').
[prefixes] refjournal=RFJOURNAL refpages=RFPAGES [stored] refjournal = refpages = [aliases] refjournal = bibtex:journal bibtex:journaltitle refpages = bibtex:pages
Telling the handler what fields to extract
As of Recoll 1.23.2, the PDF handler has the capability to use pdfinfo for extracting XMP metadata. The switch for executing pdfinfo is the 'pdfextrameta' configuration parameter, and the value of the parameter is a list of XMP tags to extract, with optional conversion to Recoll field names (the XMP qualified tag name is kept by default, the translation is separated by a '|' character). Example (without translations):
pdfextrameta = bibtex:year bibtex:journal bibtex:journaltitle
Note that it is quite equivalent to translate a field name inside 'pdfextrameta' or to uses aliases inside the 'fields' file.
Editing the field values
Shortly after the 1.23.2 release, the new rclpdf.py was modified to enable calling external Python code for editing the values of the XMP metadata fields. The name of the external script is defined by the 'pdfextrametafix' configuration variable, and it should define a 'MetaFixer' class, with a 'metafix()' method.
In practise, add the following to recoll.conf:
pdfextrametafix = /path/to/my/script.py
The Python script could look like the following:
import sys
import re
# This can be used for local XMP field editing.
#
# A new instance is created for each PDF document (so the object could
# keep state to avoid, e.g. duplicate values)
#
# The metafix method receives an (original) field name, and the text
# value, and should return the possibly modified text.
class MetaFixer(object):
def __init__(self):
pass
def metafix(self, nm, txt):
if nm == 'bibtex:pages':
txt = re.sub(r'--', '-', txt)
elif nm == 'someothername':
# do something else
pass
elif nm == 'stillanother':
# etc.
pass
return txt
The metadata-editing script can be modified to fill in the "journal" field for BibTex entries that aren’t journal articles (e.g. bibtex:booktitle for "InCollection" entries), by defining a 'wrapup()' method which will be called with the whole metadata array (an array of '(nm,value)' pairs) for global editing/removing/addition.
Indexing
Then index away!
Note that you can also run the rclpdf.py script manually,
e.g. rclpdf.py -d /path/to/some.pdf, to inspect the
output. If things are working correctly, the <head> consists of the
HTML meta elements, and the <body> contains the text of the PDF.
Result paragraph format
The result paragraph format defines what fields are displayed inside Recoll result list, and how they are formatted.
Edit this using the Recoll GUI: Preferences > GUI configuration > Result List > Edit result paragraph format string.
<table class="respar" style="padding-bottom: 10px;" cellspacing="5" cellpadding="5">
<thead style="vertical-align: top;">
<tr>
<td colspan="3" style="border-bottom: 1pt dotted #004070; font-size: smaller;"><a href="E%N">%u</a> | %S | Relevanz: %R</td>
</tr>
</thead>
<tbody style="vertical-align: top;">
<tr>
<td><a href="P%N"><img src="%I" alt="" width="64" height="auto" /></a></td>
<td style="width: 250px;"><span style="color: #004070;">
<div style="font-style: italic;">%(author)</div>
<div style="font-weight: bold;"><a href="E%N">»%T«</a></div>
<div style="text-transform: uppercase; margin-top: 5pt">%(reftype)</div></td>
<td>
<div style="font-size: smaller;">
%(refauthor)%(refchapter) %(reftitle)%(refeditor)%(refbooktitle)%(refjournal)%(refvolume)%(refnumber)%(refaddress)%(reflocation)%(refpublisher)%(refyear)%(refpages).</div>
<div style="text-align: justify; font-family: serif; margin-top: 5pt; margin-bottom: 5pt">»<a href="A%N">%A</a>«</div>
<div>%(refkeywords)</div>
<div style="font-size: smaller;"><a href="%(refurl)">%(refurl)</a></div>
<div style="font-size: smaller"> %(refkey) %(refisbn) %(refissn) %(refdoi)</div></td>
</tr>
</tbody>
</table>
And the result list header (Preferences > GUI configuration > Result List > Result Page HTML header insert):
<!-- Custom Header -->
<script type="text/javascript">
function altRows() {
var rows = document.getElementsByClassName("rclresult");
for (i = 0; i < rows.length; i++) {
if (i % 2 == 0) {
rows[i].style.backgroundColor = "#f0f0f0";
}
}
}
window.onload = function() {
altRows();
}
</script>
<style type="text/css">
a:link {
color: #004070;
text-decoration: none;
}
a:visited {
color: #004070;
text-decoration: none;
}
a:hover {
color: #0050a0;
text-decoration: none;
}
a:active {
color: #005080;
text-decoration: none;
}
</style>
<!-- End of Custom Header -->
There are various methods for creating the thumbnails; the ones here were made by opening the directory containing the PDFs in the Dolphin file manager (part of KDE) and selecting the Preview option.
And the result:
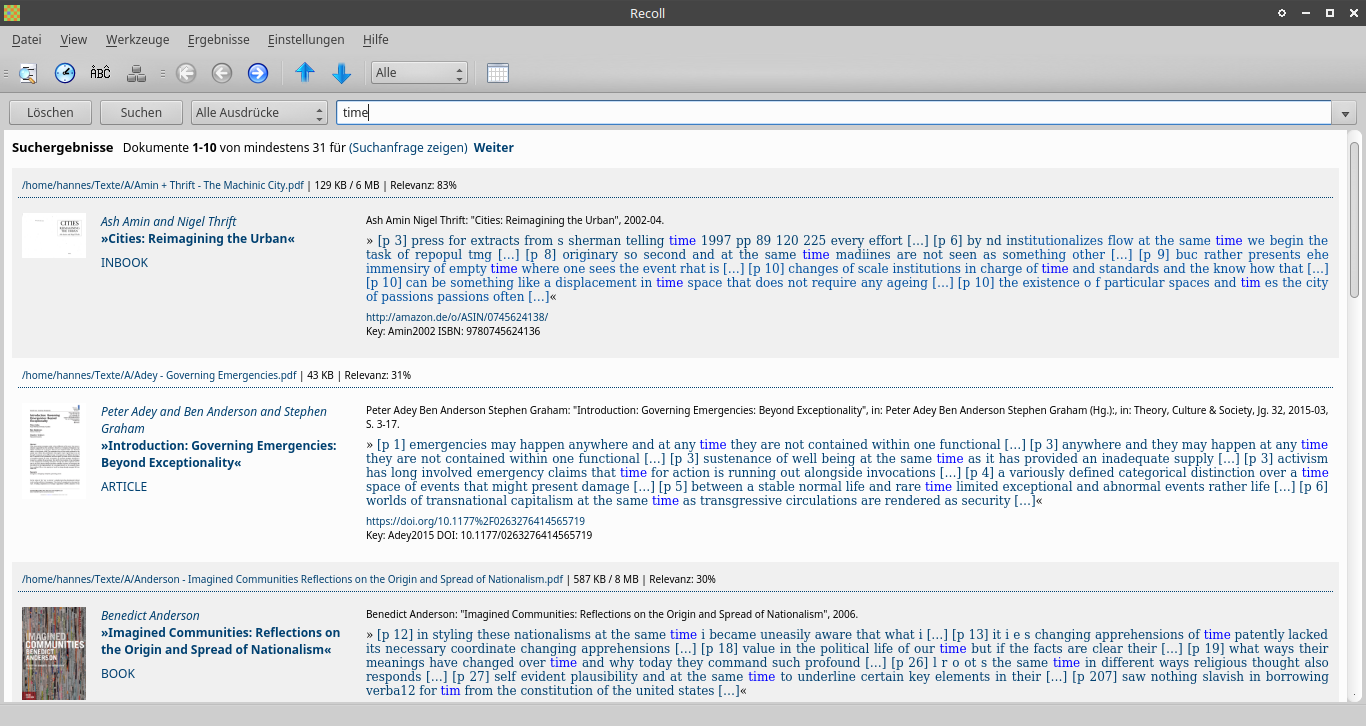
More possibilities
-
The sort buttons (up- and down-arrows) in Recoll sort the results by the modified date on the file at the time of indexing. If you want this sorting to reflect the publication year, then the timestamp should be set accordingly. If names of the PDFs contain the year (e.g. BZS2007.pdf, CKE+2011.pdf), the following one-liner would set the modified date to January 1st of the year:
for i in `ls *.pdf`; do touch -d `echo $i | sed 's/[^0-9]*//g'`-01-01 $i; done
Note that the publication year could then be shown in the result list using the stored date of the file (using "%D" in the result paragraph format, and date format "%Y") instead of having to add the year to the index as shown above.
Complete example
This was designed by Johannes Menzel, who kindly provided the data when we worked on improving PDF XMP data extraction. The originals are listed in this BitBucket issue
The paragraph format is listed above.
'recoll.conf' additions:
pdfextrameta = bibtex:journal bibtex:journaltitle bibtex:pages \ bibtex:volume bibtex:number bibtex:booktitle bibtex:year bibtex:author \ bibtex:title bibtex:isbn bibtex:issn bibtex:editor bibtex:address \ bibtex:location bibtex:doi bibtex:chapter bibtex:url bibtex:entrytype \ bibtex:bibtexkey bibtex:abstract bibtex:date bibtex:keywords \ bibtex:comment bibtex:language bibtex:edition bibtex:totalpages \ dc:creator dc:relation dc:publisher dc:title dc:type dc:identifier defaultcharset = UTF-8// pdfextrametafix = /home/hannes/.recoll/metafix.py
'metafix.py' script:
import sys
import re
# This can be used for local XMP field editing.
#
# A new instance is created for each PDF document (so the object could
# keep state to avoid, e.g. duplicate values)
#
# The metafix method receives an (original) field name, and the text
# value, and should return the possibly modified text.
class MetaFixer(object):
def __init__(self):
pass
def metafix(self, nm, txt):
if nm == 'bibtex:pages':
txt = re.sub(r'--', '-', txt)
txt = re.sub(r'^', ', p. ', txt)
elif nm == 'bibtex:author':
txt = re.sub(r'$', ':\ ', txt)
pass
elif nm == 'bibtex:chapter':
txt = re.sub(r'^', ', in: id.: ', txt)
pass
elif nm == 'bibtex:editor':
txt = re.sub(r'^', ', in: ', txt)
txt = re.sub(r'$', ' (ed.):\ ', txt)
pass
elif nm == 'bibtex:year':
txt = re.sub(r'^', ', ', txt)
pass
elif nm == 'bibtex:date':
txt = re.sub(r'^', ', ', txt)
pass
elif nm == 'bibtex:volume':
txt = re.sub(r'^', ', vol. ', txt)
pass
elif nm == 'bibtex:number':
txt = re.sub(r'^', ', no. ', txt)
pass
elif nm == 'bibtex:journaltitle':
txt = re.sub(r'^', ', in: ', txt)
pass
elif nm == 'bibtex:journal':
txt = re.sub(r'^', ', in: ', txt)
pass
elif nm == 'bibtex:title':
txt = re.sub(r'^', '"', txt)
txt = re.sub(r'$', '"', txt)
pass
elif nm == 'bibtex:location':
txt = re.sub(r'^', ', ', txt)
txt = re.sub(r'$', ':\ ', txt)
pass
elif nm == 'bibtex:address':
txt = re.sub(r'^', ', ', txt)
txt = re.sub(r'$', ':\ ', txt)
pass
elif nm == 'bibtex:isbn':
txt = re.sub(r'^', 'ISBN: ', txt)
pass
elif nm == 'bibtex:issn':
txt = re.sub(r'^', 'ISSN: ', txt)
pass
elif nm == 'bibtex:doi':
txt = re.sub(r'^', 'DOI: ', txt)
pass
elif nm == 'bibtex:bibtexkey':
txt = re.sub(r'^', 'Key: ', txt)
pass
return txt
'fields' file:
[prefixes] refjournal=RFJOURNAL refpages=RFPAGES reftitle=RFTTITLE refvolume=RFVOLUME refauthor=RFAUTHOR refyear=RFYYEAR refisbn=RFISBN refissn=RFISSN refdoi=RFDOI refeditor=RFEDITOR refpublisher=RFPUBLISHER refaddress=RFADDRESS reflocation=RFLOCATION refbooktitle=RFBOOKTITLE refurl=RFURL reftype=RFTYPE refkey=RFKEY refabstract=RFABSTRACT refkeywords=RFKEYWORDS refcomment=RFCOMMENT refedition=RFEDITION reflanguage=RFLANGUAGE [stored] refjournal= refpages= reftitle= refvolume= refauthor= refyear= refisbn= refissn= refdoi= refeditor= refpublisher= refaddress= reflocation= refbooktitle= refurl= reftype= refkey= refabstract= refkeywords= refcomment= refedition= reflanguage= refid= [aliases] refjournal = bibtex:journal bibtex:journaltitle refpages = bibtex:pages reftitle = bibtex:title refvolume = bibtex:volume refauthor = bibtex:author refyear = bibtex:year bibtex:date refid = dc:identifier bibtex:isbn bibtex:issn refisbn = bibtex:isbn refissn = bibtex:issn refdoi = bibtex:doi refeditor = bibtex:editor refpublisher = bibtex:publisher refaddress = bibtex:address reflocation = bibtex:location refbooktitle = bibtex:booktitle refurl = bibtex:url reftype = bibtex:entrytype bibtex:type refkey = bibtex:bibtexkey refabstract = bibtex:abstract refkeywords = bibtex:keywords refcomment = bibtex:comment refedition = bibtex:edition reflanguage = bibtex:language author = xesam:author