
A history of dividing indexing time by $ncpus
Abstract
This relates how the Recoll document indexer was converted to use multiple CPUs through multithreading.
Introduction
Recoll is a document indexing application, it allows you to find documents by specifying search terms.
The documents need to be indexed for searches to be fast. In a nutshell, we convert the different document formats to text, then split the text into terms and remember where those occur. This is a time-consuming operation.
Up to version 1.18 Recoll indexing is single-threaded: routines which call each other sequentially.
In most personal indexer contexts, it is also CPU-bound. There is a lot of conversion work necessary for turning those PDF (or other) files into appropriately cleaned up pure text, then split it into terms and update the index. Given the relatively modest amount of data, and the speed of storage, I/O issues are secondary.
Looking at the CPU idle top output stuck at 75% on my quad-core CPU, while waiting for the indexing to finish, was frustrating, and I was tempted to find a way to keep those other cores at temperature and shorten the waiting.
For some usages, the best way to accomplish this may be to just partition the index and independantly start indexing on different configurations, using multiple processes to better utilize the available processing power.
This is not an universal solution though, as it is complicated to set up, not optimal in general for indexing performance, and not always optimal either at query time.
The most natural way to improve indexing times is to increase CPU utilization by using multiple threads inside an indexing process.
Something similar had been done with earlier versions of the Recoll GUI, which had an internal indexing thread. This had been a frequent source of trouble though, and linking the GUI and indexing process lifetimes was a bad idea, so, in recent versions, the indexing is always performed by an external process. Still, this experience had put in light most of the problem areas, and prepared the code for further work.
It should be noted that, as recollindex is both nice'd and ionice'd
as a lowest priority process, it will only use free computing power on the
machine, and will step down as soon as anything else wants to work.
In general, augmenting the machine utilisation by recollindex just does
not change its responsiveness. My PC has a an Intel Pentium Core i5 750 (4
cores, no hyperthreading), which is far from being a high performance CPU
(nowadays…), and I often forget that I am running indexing tests, it is
just not noticeable. The machine does have a lot of memory though (12GB).
The Recoll indexing processing flow
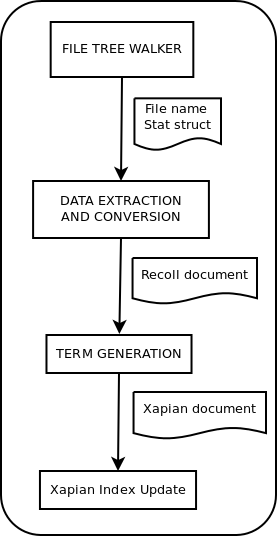
There are 4 main steps in the recollindex processing pipeline:
-
Find the file
-
Convert it to text
-
Process the text (split, strip etc.) and create a Xapian document
-
Update the index
The first step, walking the file system (or some other data source), is usually much faster than the others, and we just leave it alone to be performed by the main thread. It outputs file names (and the associated POSIX stat data).
The last step, Xapian index updating, can only be single-threaded.
The first idea is to change the indexing pipeline so that each step is performed by an independant worker thread, passing its output to the next thread, in assembly-line fashion.
In order to achieve this, we need to decouple the different phases. They are normally linked by procedure calls, which we replace with a job control object: the 'WorkQueue'.
The WorkQueue
The WorkQueue object is implemented by a reasonably simple class, which manages an input queue on which client append jobs, and a set of worker threads, which retrieve and perform the jobs, and whose lifetime are managed by the WorkQueue object. The implementation is straightforward with POSIX threads synchronization functions and C++ STL data structures.
In practise it proved quite simple to modify existing code to create a job object and put it on the queue, instead of calling the downstream routine with the job parameters, while keeping the capacity to call the downstream routine directly. The kind of coupling is determined either by compilation flags (for global disabling/enabling of multithreading), or according to configuration data, which allows experimenting with different threads arrangements just by changing parameters in a file, without recompiling.
Each WorkQueue accepts two parameters: the length of the input queue (before a client will block when trying to add a job), and the number of worker threads. Both parameters can be set in the Recoll configuration file for each of the three queues used in the indexing pipeline. Setting the queue length to -1 will disable the corresponding queue (using a direct call instead).
unfloat::[]
The Assembly Line
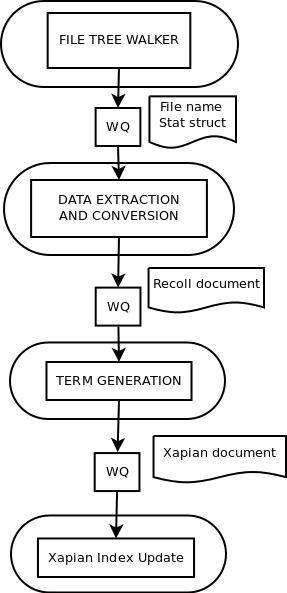
So the first idea is to create 3 explicit threads to manage the file conversion, the term generation, and the Xapian index update. The first thread prepares a file, passes it on to the term generation thread, and immediately goes back to work on the next file, etc.
The presumed advantage of this method is that the different stages, which perform disjointed processing, should share little, so that we can hope to minimize the changes necessitated by the threads interactions.
However some changes to the code were needed to make this work (and a few bugs were missed, which only became apparent at later stages, confirming that the low interaction idea was not completely false).
Converting to multithreading: what to look for
I am probably stating the obvious here, but when preparing a program for multi-threading, problems can only arise where non-constant data is accessed by different threads.
Once you have solved the core problems posed by the obvious data that needs to be shared, you will be left to deal with less obvious, hidden, interactions inside the program.
Classically this would concern global or static data, but in a C++ program, class members will be a concern if a single object can be accessed by several threads.
Hunting for static data inside a program of non trivial size is not always obvious. Two approaches can be used: hunting for the static keyword in source code, or looking at global and static data symbols in nm output.
Once found, there are mostly three types of static/global data:
-
Things that need to be eliminated: for example, routines can be made reentrant by letting the caller supply a storage buffer instead of using an internal static one (which was a bad idea in the first place anyway).
-
Things that need to be protected: sometimes, the best approach is just to protect the access with a mutex lock. It is trivial to encapsulate the locks in C objects to use the "Resource Acquisition is Initialization" idiom, easily making sure that locks are freed when exiting the critical section. Recoll used to include a basic home-made implementation, but now lets C11 work for it.
-
Things which can stay: this is mostly initialization data such as value tables which are computed once, and then stay logically constant during program execution. In order to be sure of a correct single-threaded initialization, it is best to explicitly initialize the modules or functions that use this kind of data in the main thread when the program starts.
Assembly line approach: the results
Unfortunately, the assembly line approach yields very modest improvements when used inside Recoll indexing. The reason, is that this method needs stages of equivalent complexity to be efficient. If one of the stages dominates the others, its thread will be the only one active at any time, and little will be gained.
What is especially problematic is that the balance between tasks need not only exist on average, but also for the majority of individual jobs.
For Recoll indexing, even if the data preparation and index update steps are often of the same order of magnitude on average, their balance depends a lot on the kind of data being processed, so that things are usually unbalanced at any given time: the index update thread is mostly idle while processing PDF files, and the data preparation has little to do when working on HTML or plain text.
In practice, very modest indexing time improvements from 5% to 15% were achieved with this method.
The next step: multi-stage parallelism
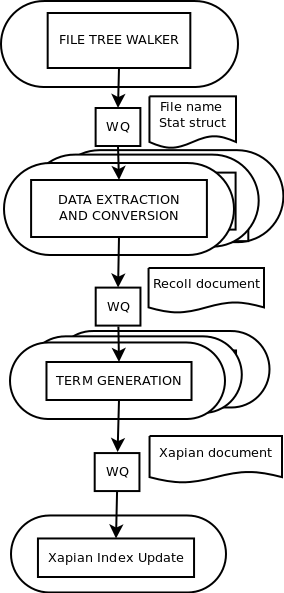
Given the limitations of the assembly line approach, the next step in the transformation of Recoll indexing was to enable full parallelism wherever possible.
Of the four processing steps (see figures), two are not candidates for parallelization:
-
File system walking is so fast compared to the other steps that using several threads would make no sense (it would also quite probably become IO bound if we tried anyway).
-
The Xapian library index updating code is not designed for multi-threading and must stay protected from multiple accesses.
The two other steps are good candidates.
Most of the work to make Recoll code reentrant had been performed for the previous transformation. Going full-parallel only implied protecting the data structures that needed to be shared by the threads performing a given processing step.
Just for the anecdotic value, a list of the elements that needed mutexes:
-
Filter subprocesses cache: some file conversion subprocesses may be expensive (starting a Python process is no piece of cake), so they are cached for reuse after they are done translating a file. The shared cache needs protection.
-
Status updates: an object used to update the current file name and indexing status to a shared file.
-
Missing store: the list of missing helper programs
-
The readonly Xapian database object: a Xapian::Database object which is used for checking the validity of current index data against a file’s last modification date.
-
Document existence map: a bit array used to store an existence bit about every document, and purge the disappeared at the end of the indexing pass. This is accessed both from the file conversion and database update code, so it also needed protection in the previous assembly line approach.
-
Mbox offsets cache. Used to store the offsets of individual messages inside mbox files.
-
iconv control blocks: these are cached for reuse in several places, and need protection. Actually, it might be better in multithreading context to just suppress the reuse and locking. Rough tests seem to indicate that the impact on overall performance is small, but this might change with higher parallelism (or not…).
The Recoll configuration also used to be managed by a single shared object, which is mutable as values may depend on what area of the file-system we are exploring, so that the object is stateful and updated as we change directories. The choice made here was to duplicate the object where needed (each indexing thread gets its own). This gave rise to the sneakiest bug in the whole transformation (see further down).
Having a dynamic way to define the threads configuration makes it easy to experiment. For example, the following data defines the configuration that was finally found to be best overall on my hardware:
thrQSizes = 2 2 2 thrTCounts = 4 2 1
This is using 3 queues of depth 2, 4 threads working on file conversion, 2 on text splitting and other document processing, and 1 on Xapian updating (no choice here).
unfloat::[]
Bench results
So the big question after all the work: was it worth it ? I could only get a real answer when the program stopped crashing, so this took some time and a little faith, but the answer is positive, as far as I’m concerned. Performance has improved significantly and this was a fun project.
Update much later: the following tests were probably run with Xapian 1.2.x.
| Area | Seconds before | Seconds after | Percent Improvement | Speed Factor |
|---|---|---|---|---|
home |
12742 |
6942 |
46% |
1.8 |
2700 |
1563 |
58% |
1.7 |
|
projets |
5022 |
1970 |
61% |
2.5 |
2164 |
770 |
64% |
2.8 |
|
otherhtml |
5593 |
4014 |
28% |
1.4 |
| Area | Files MB | Files | DB MB | Documents |
|---|---|---|---|---|
home |
64106 |
44897 |
1197 |
104797 |
813 |
232 |
663 |
47267 |
|
projets |
2056 |
34504 |
549 |
40281 |
1123 |
1139 |
111 |
1139 |
|
otherhtml |
3442 |
223007 |
2080 |
221890 |
home is my home directory. The high megabyte value is due to a number of very big and not indexed VirtualBox images. Otherwise, it’s a wide mix of source files, email, miscellaneous documents and ebooks.
mail is my mail directory, full of mbox files.
projets mostly holds source files, and a number of documents.
pdf holds random pdf files harvested on the internets. The performance is quite spectacular, because most of the processing time goes to converting them to text, and this is done in parallel. Probably could be made a bit faster with more cores, until we hit the Xapian update speed limit.
otherhtml holds myriad of small html files, mostly from wikipedia. The improvement is not great here because a lot of time is spent in the single-threaded Xapian index update.
The tests were made with queue depths of 2 on all queues, and 4 threads working on the file conversion step, 2 on the term generation.
A variation: linear parallelism
Once past the assembly-line idea, another possible transformation would be to get rid of the two downstream queues, and just create a job for each file and let it go to the end (using a mutex to protect accesses to the writable Xapian database).
With the current Recoll code, this can be defined by the following parameters (one can also use a deeper front queue, this changes little):
thrQSizes = 2 -1 -1 thrTCounts = 4 0 0
In practise, the performance is close to the one for the multistage version.
If we were to hard-code this approach, this would be a simpler modification, necessitating less changes to the code, but it has a slight inconvenient: when working on a single big multi-document file, no parallelism at all can be obtained. In this situation, the multi-stage approach brings us back to the assembly-line behaviour, so the improvements are not great, but they do exist.
The Xapian bottleneck and how it was resolved (thanks to Xapian…)
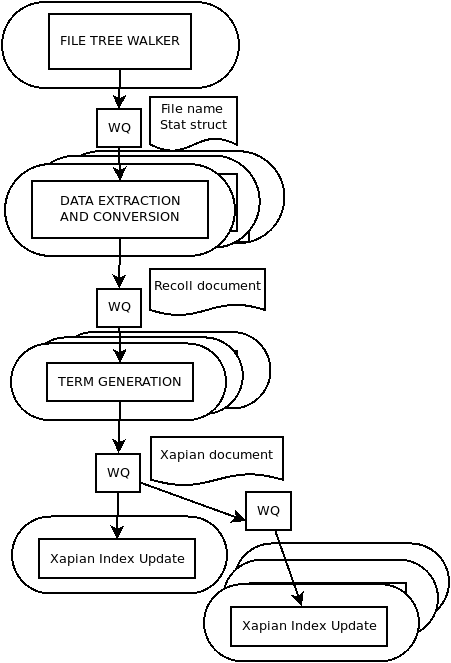
Xapian index updates can only performed by a single thread. Depending on the nature of the document set, this may be more or less of an issue: if the input documents need a lot of processing, the index updates may not slow down the whole process.
When the input documents need only light processing though (for example, for indexing HTML or text files), the index updates become the bottleneck, and only the equivalent of two CPU cores may be in use at most, and often less, e.g. during the index flushes. In this situation, multithreading actually just yields a minor improvement to the total indexing time.
The brute force solution is to partition the document set and perform indexing by using multiple processes, each working on a document subset and a separate index.
However, Xapian has a compact() function which allows reading in multiple indexes and merging them
into a single output, and this function is very fast.
The last stage of the indexer was modified to create multiple temporary indexes, dispatch the added documents into them during the index update, and finally merge the temporary indexes and the initial one into the result.
This process only produces improvements if many documents are added, because existing modified documents need to be updated into the original index. It is at its best for initial indexing, where the original index is, and remains, empty until the final merge. In fact, in this very special case, the main index could be the target of the merge, but this would complicate the code for little practical gain.
Here are the results for the initial indexing of a partial Wikipedia dump, using a CPU with 4 cores
and hyperthreading (Intel core i7-8550U). All the data is stored on SSDs. The CPU times listed are
the total of the whole processing, from reading the files to finalizing the indexes, as printed by
time.
The following tests were run with Xapian 1.4.18 on an Ubuntu 22.04 system.
| Threading | Temp. indexes | Real time, Seconds | Percent Change | Speed Factor | CPU time, Seconds |
|---|---|---|---|---|---|
off |
0 |
1129 |
0% |
1 |
1057 |
on |
0 |
881 |
-22% |
1.3 |
1486 |
on |
4 |
397 |
-64% |
2.8 |
1782 |
This is of course a quite significant improvement, using a very simple change, a couple hundred lines of code, a lot of it dealing with moving files around at the end.
Conversely, if the input is only made of PDF files, this approach makes things worse, but not by too much:
| Threading | Temp. indexes | Real time, Seconds | Percent Change | Speed Factor | CPU time, Seconds |
|---|---|---|---|---|---|
on |
0 |
1652 |
0% |
1 |
7105 |
on |
4 |
1698 |
+3% |
0.97 |
7580 |
On mixed inputs, we get intermediate improvements.
Miscellany
The big gotcha: my stack dump staring days
Overall, debugging the modified program was reasonably straightforward. Data access synchronization issues mostly provoke dynamic data corruption, which can be beastly to debug. I was lucky enough that most crashes occurred in the code that was actually related to the corrupted data, not in some randomly located and unrelated dynamic memory user, so that the issues were reasonably easy to find.
One issue though kept me working for a few days. The indexing process kept crashing randomly at an interval of a few thousands documents, segfaulting on a bad pointer. An access to the configuration data structure seemed to be involved, but, as each thread was supposed to have its own copy, I was out of ideas.
After reviewing all the uses for the configuration data (there are quite a few), the problem was finally revealed to lie with the filter process cache. Each filter structure stored in the cache stores a pointer to a configuration structure. This belonged to the thread which initially created the filter. But the filter would often be reused by a different thread, with the consequence that the configuration object was now accessed and modified by two unsynchronized threads… Resetting the config pointer at the time of filter reuse was a very simple (almost)single-line fix to this evasive problem.
Looking at multi-threaded stack dumps is mostly fun for people with several heads, which is unfortunately not my case, so I was quite elated when this was over.
Fork performance issues
On a quite unrelated note, something that I discovered while evaluating the
program performance is that forking a big process like recollindex can be
quite expensive. Even if the memory space of the forked process is not
copied (it’s Copy On Write, and we write very little before the following
exec), just duplicating the memory maps can be slow when the process uses a
few hundred megabytes.
I actually wrote another quite lengthy text on the subject. The TL:DR is that the problem was addressed by very carefully using vfork in addition to slave processes.